객체를 SQL로 변환하는 단순한 일부터, 객체의 상속 구조를 테이블에 저장하는 복잡할 일까지 개발자는 객체와 데이터베이스 사이에서 무수한 매핑 코드와 SQL을 작성해야 했다. 자바 진영에서는 이런 문제를 해결하기 위해 JPA라는 표준 기술을 제공한다.

개요
서두에 이어 조금 더 깊게 들어가 보자. 지난날 우리는 무수히 많은 CRUD의 반복, 객체와 데이터베이스 매핑관계의 반복 등 지루한 코드를 계속해서 작성하였다. 이러한 문제로 인해 자바 ORM 표준 JPA가 탄생하였고, JPA를 사용하여 SQL 작성 없이 객체를 데이터베이스에 직접 저장할 수 있게 하고, 객체와 관계형 데이터베이스의 차이도 중간에서 해결하게 만들었다.
궁극적으로 JPA를 사용해서 얻은 가장 큰 성과는 애플리케이션을 SQL이 아닌 객체 중심으로 개발하니 생산성과 유지보수가 확연히 좋아졌고 테스트를 작성하기도 편리해진 점이다.
JPA를 사용하기 전에는 우린 어떤 문제를 겪고 있었을까?
SQL을 직접 다룰 때 발생하는 문제점🏥
회원을 조회하는 코드를 예시로 들어보자. 첫 번째로 데이터베이스에서 원하는 회원을 조회하는 SQL을 작성한다.
SELECT MEMBER_ID, NAME FROM MEMBER M WHERE MEMBER_ID = ?두번째로, JDBC API를 사용해서 SQL을 실행한다.
ResultSet rs = stmt.executeQuery(sql);마지막으로 조회 결과를 Member 객체로 매핑한다.
String memberId = rs.getString("MEMBER_ID");
String name = rs.getString("NAME");
Member member = new Member();
member.setMemberId(memberId);
member.setName(name);
...이 밖의 회원 등록 기능, 수정 기능도 비슷한 로직으로 형성이 될 것이다. 하지만 만약 회원에 이메일 필드가 추가된다면?
사실 어렵지는 않다. Entity와 DTO에 이메일 필드를 추가하고, SQL문에 해당 필드만 추가하면 되기 때문이다. 하지만 여기서 중요한 점은, 문제가 발생했을 때 전적으로 DAO에 의존해야 한다는 것이다. 쉬운 예시를 들자면, 조회할 때 추가한 Email 필드가 null이 나왔을 때, 우리는 SQL을 직접 눈으로 확인해서 값이 안 나오는 이유를 찾아야 한다는 것이다.
이런식의 개발 방식은 SQL에 의존적으로 개발하는 문제가 있다. 필드 하나만 추가해도 등록,수정,조회 등의 관련된 모든 비즈니스 로직들을 하나하나 실행하면서 수정해야 한다는 점이다. 추후에는 Entity를 신뢰할 수 없게 될 것이다.
JPA는 어떻게 해결할까?💊
JPA를 사용하면 객체를 데이터베이스에 저장하고 관리할 때, 개발자가 직접 SQL을 작성하는 것이 아니라 JPA가 제공하는 API를 사용하면 된다. 그러면 JPA가 개발자 대신에 적절한 SQL을 생성해서 데이터베이스에 전달한다. 그럼 JPA가 제공하는 CRUD API는 어떤 게 있을까?
1. 저장 기능
jpa.persist(member); // 저장persist() 메소드는 객체를 데이터베이스에 저장한다. 이 메소드를 호출하면 JPA가 객체와 매핑정보를 받고 적절한 INSERT SQL을 생성해서 데이터베이스에 전달한다.
2. 조회 기능
String memberId = "Binco";
Member member = jpa.find(Member.class, memberId); // 조회find() 메소드는 객체 하나를 데이터베이스에서 조회한다. JPA는 객체와 매핑정보를 보고 적절한 SELECT SQL을 생성해서 데이터베이스에 전달하고 그 결과로 Member 객체를 생성해서 반환한다.
3. 수정 기능
String memberId = "Binco";
Member member = jpa.find(Member.class, memberId);
member.setName("Tistory"); // 수정JPA는 별도의 수정 메소드를 제공하지 않는다. 대신에 객체를 조회해서 값을 변경만 하면 트랜잭션을 커밋할 때 데이터베이스에 적절한 UPDATE SQL이 전달된다. 이 부분은 변경 감지(Dirty Checking)이라고 한다. 단순 JPA 메서드만 설명하는 포스팅이어서 궁금하신 분은 관련 포스팅을 클릭해주세요😄
4. 연관된 객체 조회
String memberId = "Tistory";
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam(); // 연관된 객체 조회JPA는 연관된 객체를 사용하는 시점에 적절한 SELECT SQL을 실행한다. 따라서 JPA를 사용하면 연관된 객체를 마음껏 조회할 수 있다. 이 부분도 JPA의 fetch Type인 Eager Loading, Lazy Loading을 통해 이루어지는데, 포스팅의 범위가 아니므로 궁금하신 분은 관련 포스팅을 클릭해주세요😁
또 다른 문제 패러다임 불일치💥
객체는 속성(필드)과 기능(메소드)를 가진다. 객체의 기능은 클래스에 정의되어 있으므로 객체 인스턴스의 상태인 속성만 저장했다가 필요할 때 불러와서 복구하면 된다. 객체가 단순하면 객체의 모든 속성 값을 꺼내서 파일이나 데이터베이스에 저장하면 되지만, 부모 객체를 상속받았거나, 다른 객체를 참조하고 있다면 객체의 상태를 저장하기는 쉽지 않다.
예를 들어 회원 객체를 저장해야 하는데 회원 객체가 팀 객체를 참조하고 있다면, 회원 객체를 저장할 때 팀 객체도 함께 저장해야 한다. 단순히 회원 객체만 저장하면 참조하는 팀 객체를 잃어버리는 문제가 발생한다.
대안으로는 관계형 데이터베이스에 객체를 저장하는 방법이 있는데, 관계형 데이터베이스는 데이터 중심으로 구조화되어 있고, 집합적인 사고를 요구한다. 그리고 객체지향에서 이야기하는 추상화,상속,다향성 같은 개념이 없다.
객체와 관계형 데이터베이스는 지향하는 목적이 서로 다르므로 둘의 기능과 표현 방법도 다르다. 이것을 객체와 관계형 데이터베이스의 패러다임 불일치 문제라 한다. 따라서 객체 구조를 테이블 구조에 저장하는 데는 한계가 있다.
개발자는 이러한 패러다임의 불일치 문제를 중간에서 해결해야 한다. 문제는 이런 객체와 관계형 데이터베이스 사이의 패러다임 불일치 문제를 해결하는 데 너무 많은 시간과 코드를 소비한다.
상속(inheritance)
위 그림처럼 객체는 상속이라는 기능을 가지고 있지만 테이블은 상속이라는 기능이 없다. 그나마 데이터 베이스 모델링에서 이야기하는 슈퍼타입 서브타입 관계를 사용하면 객체 상속과 가장 유사한 형태로 테이블을 설계할 수 있다.
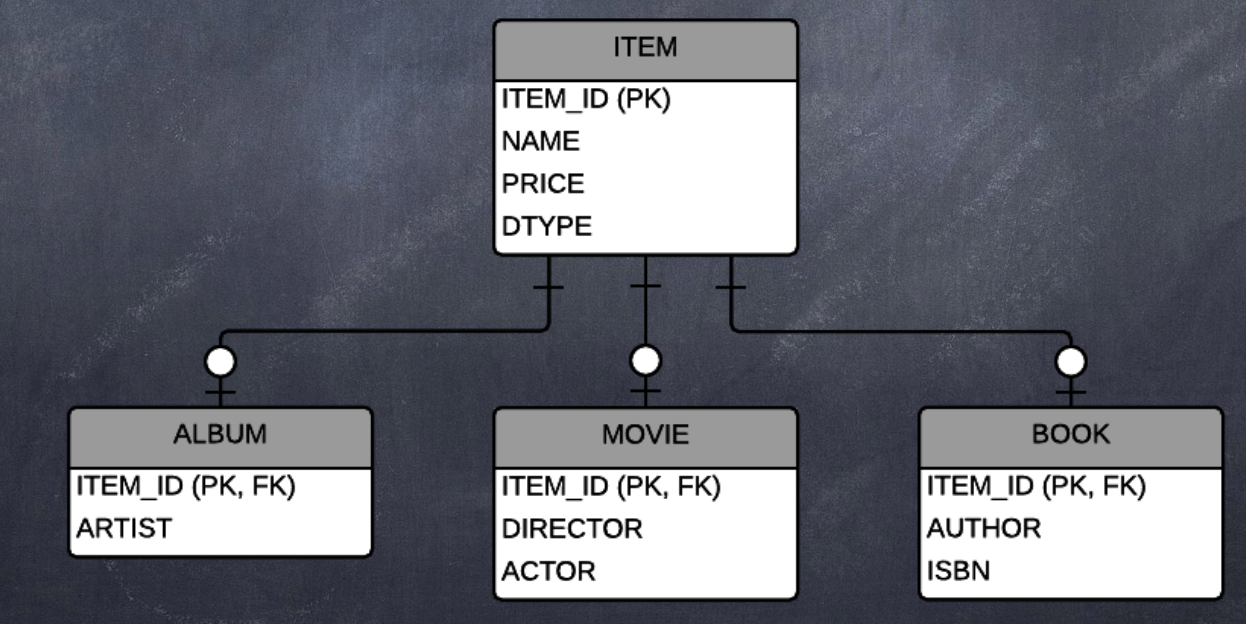
위 그림처럼 ITEM 테이블의 DTYPE 컬럼을 사용해서 어떤 자식 테이블과 관계가 있는지 정의했다. 예를 들어 DTYPE 값이 MOVIE이면 영화 테이블과 관계가 있는 것이다.
abstract class Item {
Long id;
String name;
int price;
}
class Album extends Item {
String artist;
}
class Movie extends Item {
String director;
String actor;
}
class Book extends Item {
String author;
String isbn;
}
객체 모델 코드는 위와 같을 것이다. 만약 JPA를 사용하지 않고 영화 한 건을 저장하려면 SQL문은 어떻게 작성해야 할까? Movie 객체를 저장하려면 이 객체를 분해해서 다음 두 SQL을 만들어야 했다.
INSERT INTO ITEM ...
INSERT INTO MOVIE ...
기존의 JDBC API를 사용해서 이 코드를 완성하려면 부모 객체에서 부모 데이터만 꺼내서 ITEM용 INSERT SQL을 작성하고 자식 객체에서 자식 데이터만 꺼내서 MOVIE용 INSERT SQL을 작성해야 하는데, 작성해야 할 코드량이 만만치 않다. 그리고 자식 타입에 따라서 DTYPE도 저장해야 한다.
이렇게 등록 기능 뿐만 아니라, 조회하는 것도 매한가지로 쉬운 일은 아니다. 이러한 모든 과정이 패러다임의 불일치를 해결하려고 소모하는 비용이다. JPA는 상속과 관련된 패러다임의 불일치 문제를 개발자 대신 해결해준다. 개발자는 마치 자바 컬렉션에 객체를 저장하듯이 JPA에게 객체를 저장하면 된다.
그저 persist() 메소드만 사용하면 JPA가 나머지 부분을 해결해준다는 것이다.
연관 관계(relationship)
객체는 참조를 사용해서 다른 객체와 연관관계를 가지고 참조에 접근해서 연관된 객체를 조회한다. 반면에 테이블은 외래 키를 사용해서 다른 테이블과 연관관계를 가지고 조인을 사용해서 연관된 테이블을 조회한다.
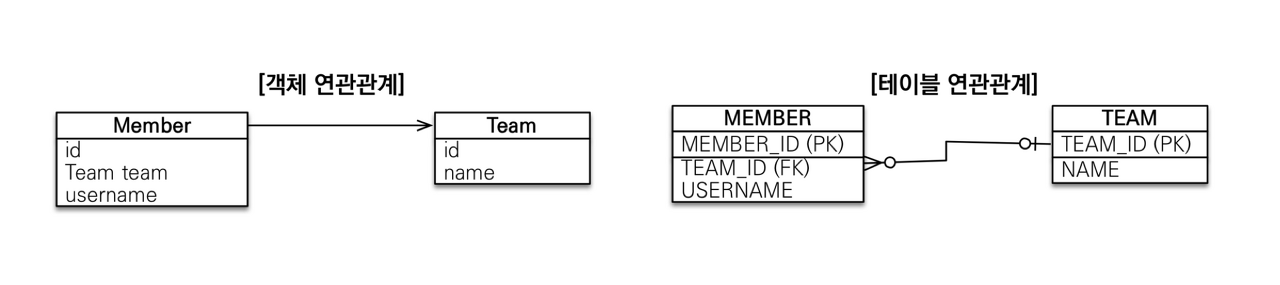
객체의 연관관계를 먼저 살펴보자면 Member 객체는 Member.team 필드에 Team 객체의 참조를 보관해서 Team 객체와 관계를 맺는다. 따라서 이 참조 필드에 접근하면 Member와 연관된 Team을 조회 할 수 있다.
class Member {
Team team;
...
Team getTeam() {
return team;
}
}
class Team {
...
}
member.getTeam(); // member -> team 접근
테이블의 연관관계를 살펴보자면 MEMBER 테이블은 MEMBER.TEAM_ID 외래 키 컬럼을 사용해서 TEAM 테이블과 관계를 맺는다. 이 외래 키를 사용해서 MEMBER 테이블과 TEAM 테이블을 조인하면 MEMBER 테이블의 연관된 TEAM 테이블을 조회 할 수 있다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
이처럼 객체와 테이블이 추구하는 방향 자체가 다르다. Member 객체는 team 필드로 연관관계를 맺고 MEMBER 테이블은 TEAM_ID 외래 키로 연관관계를 맺고 있기 때문에, 객체 모델은 외래 키가 필요 없고 단지 참조만 있으면 된다. 반면에 테이블은 참조가 필요 없고 외래 키가 있으면 된다. 결국, 개발자가 중간에서 변환 역할을 해야 한다.
public Member find(String memberId) {
// SQL 실행
...
Member member = new Member();
... // 데이터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
... // 데이터베이스에서 조회한 팀 관련 정보를 모두 입력
// 회원과 팀 관계 설정
member.setTeam(team);
return member;
}연관관계를 직접 설정해 보았다. 지금은 단순히 주석으로 처리하였지만, 만약 맴버가 가진 필드가 (이름, 나이, 이메일 등 100개 필드), 팀이 가진 필드도 100개가 넘는다고 생각한다면 셋팅하는데만 200줄의 코드가 필요하다.
이런 과정들이 모두 패러다임 불일치를 해결하려고 소모하는 비용이다. JPA는 연관관계와 관련된 패러다임의 불일치 문제를 해결해준다.
member.setTeam(team); // 회원과 팀 연관관계 설정
jpa.persist(member); // 회원과 연관관계 함께 저장
개발자는 회원과 팀의 관계를 설정하고 회원 객체를 저장하면 된다. JPA는 team의 참조를 외래 키로 변환해서 적절한 INSERT SQL을 데이터베이스에 전달한다. 객체를 조회할 때 외래 키를 참조로 변환하는 일도 JPA가 처리해준다.
연관 관계와 관련하여 객체 그래프 탐색 관련에도 JPA는 좋은 기능을 제공한다. 이 부분은 깊게 들어갈 필요가 있어서 해당 포스팅을 참고하면 좋을 것 같다😄
비교(comparison)
데이터베이스는 기본 키의 값으로 각 로우(row)를 구분한다. 반면에 객체는 동일성(identity) 비교와 동등성(equality) 비교라는 두 가지 비교 방법이 있다.
- 동일성 비교는 == 비교다. 객체 인스턴스의 주소 값을 비교한다.
- 동등성 비교는 equals() 메소드를 사용해서 객체 내부의 값을 비교한다.
따라서 테이블의 로우를 구분하는 방법과 객체를 구분하는 방법에는 차이가 있다.
// MemberDAO 코드
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
// JDBC API, SQL실행
return new Member(...);
}
}
// 조회한 회원 비교하기
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; //다르다.
반면에 JPA를 사용하면?
// member1과 member2는 동일성 비교에 성공
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId);
Member member2 = jpa.find(Member.class, memberId);
member1 == member2; //같다.
이처럼 JPA는 같은 트랜잭션 일 때 같은 객체가 조회되는 것을 보장한다.
👨👩👦👦 오픈채팅방 운영
취업을 준비하는 예비 개발자분들을 위한 질문&답변할 수 있는 공간을 만들었습니다. 취업과 이직을 하기 위해서 어떤 걸 중점적으로 준비해야 하는지부터 포트폴리오&이력서 작성법 등 다양한 질문들을 받고 답변을 드립니다. 참여하셔서 다양한 정보 얻고 가시면 좋을 것 같네요😁
참여코드 : 456456
https://open.kakao.com/o/gVHZP8dg
비전공 개발자 취업 준비방(질문&답변)
#비전공 #개발자 #취업 #멘토링 #부트캠프 #국비지원 #백엔드 #프론트엔드 #중소기업 #중견기업 #자바 #Java #sql
open.kakao.com
👨💻 전자책 출간
아울러 제가 🌟비전공자에서 2년만에 보안 전문 중견기업으로 이직 한 방법들을 정리한 전자책을 출간 하게 되었습니다. 어떤 걸 공부해야 하는지, 이직을 위해서 무엇을 준비해야 하는지, 제가 받았던 기술 면접 리스트 등 다양한 목차로 구성되어 있습니다. 또한, 구매 시 1:1 채팅을 이용하여 포트폴리오 첨삭을 도와드리고 있습니다. 🐕전자책으로 얻은 모든 수익은 유기견 센터 '팅*벨 입양센터'에 후원될 예정입니다. 관심 있으신 분들은 아래 링크를 참고해주세요😁
비전공개발자 2년만에 중견기업 들어간 방법 | 14000원부터 시작 가능한 총 평점 0점의 전자책, 취
0개 총 작업 개수 완료한 총 평점 0점인 Binco의 전자책, 취업·이직 전자책 서비스를 0개의 리뷰와 함께 확인해 보세요. 전자책, 취업·이직 전자책 제공 등 14000원부터 시작 가능한 서비스
kmong.com
마치며
지금까지 JPA를 사용해야 하는 이유와 장점들을 소개했다. 간단히 정리하면, 반복적인 CRUD 작업을 대신 해주기에 생산성이 좋고, SQL을 직접 다루지 않아도 되기에 유지보수 측면에서 좋다. 또한, 패러다임 불일치 문제를 개발자 대신에 직접 해결해주며 재사용성 면에서 뛰어난 기능을 선보인다.
Reference
'Book Review' 카테고리의 다른 글
| 자바 ORM 표준 JPA 프로그래밍 - 연관관계 매핑 (0) | 2022.10.23 |
|---|---|
| 자바 ORM 표준 JPA 프로그래밍 - 엔티티 매핑 (1) | 2022.10.08 |
| [그림으로 공부하는 IT인프라 구조] - 책 리뷰 (0) | 2022.06.27 |
| [읽기 좋은 코드가 좋은 코드다] 책 리뷰 (0) | 2022.06.14 |
| 향로님의 스프링 부트와 AWS로 혼자 구현하는 웹 서비스 (0) | 2022.06.03 |